New AI and Machine Learning (ML) solutions have become one of the most powerful tools in today’s technology stacks. These support the ability to process and analyze vast amounts of data to identify patterns and to make forecasting more reliable. AI has been driving innovation in healthcare, finance, and retail. Now, it's beginning to revolutionize the field of software engineering. This article shares some of our innovations in applying AI to software engineering processes.
Predicting Development Cycle Times
Here at Logilica Labs we always evaluate and experiment with the latest advances in engineering and technology. One such investigation we recently undertook is the application of machine learning to engineering forecast. In this article, we zoom into a particular investigation of predicting cycle times for Pull Request (PRs).
For those unfamiliar, a Pull Request is essentially the process to merge a developer’s change (new code) into the main codebase of a software project. This is a crucial part of the development process, as it allows the team to review and test typically small changes before they become part of the final product. However, the time it takes to review and merge a pull request can vary widely—sometimes it’s quick, and sometimes it’s more complicated and time-consuming.
That’s where we applied machine learning. By analyzing a large volume of past pull request data, machine learning is employed to predict how long it might take to review and merge a new PR based on certain indicator. This helps development teams to plan more effectively, avoid unexpected delays and improve overall project timelines.
How does it work?
For making pull request management more predictable we analysed vast amounts of past PRs to estimate review times, predict merging delays, and optimise workflows. Here’s what we did:
Data gathering: Firstly, we gathered features from past PRs—things like how many files were changed, how many reviewers were involved, the complexity of the code changes, and how long it took to merge a PR. It is expected that PRs with large-scale changes or extensive dependencies take longer to review and merge, while smaller updates are expected to be processed more quickly.
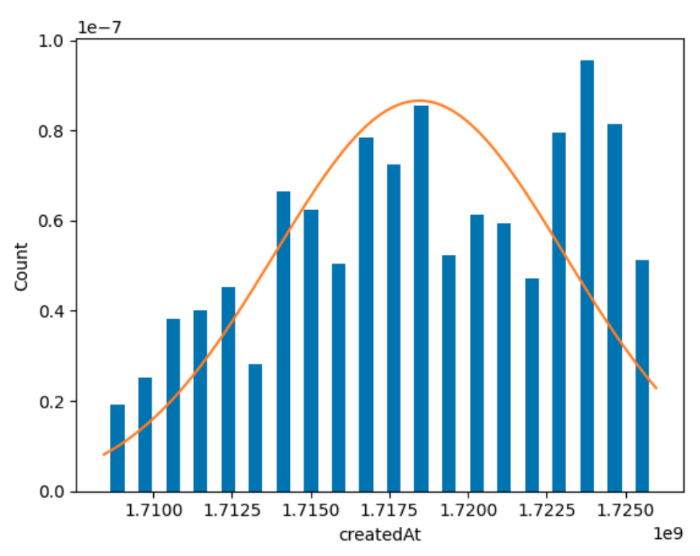
After the data gathering and extraction we sanitised and normalised it for by removing errors, ensuring consistency, and structuring it in a way that the machine learning models scan analyse it effectively. Also, we need to determine whether the data is reasonably distributed or biased towards certain extremes, that would distort model predictions, leading to les faithful results.
PRs creation distribution over time to find outliners and avoid learning bias
Model Training. Next, we trained a machine learning model using the cleaned data. The model learns patterns, like which types of PRs tend to get stuck in review, what factors lead to longer approval times, and which team members typically review faster. Once trained, it the model intends to predict how long a new PR might take to review and merge based on its features.
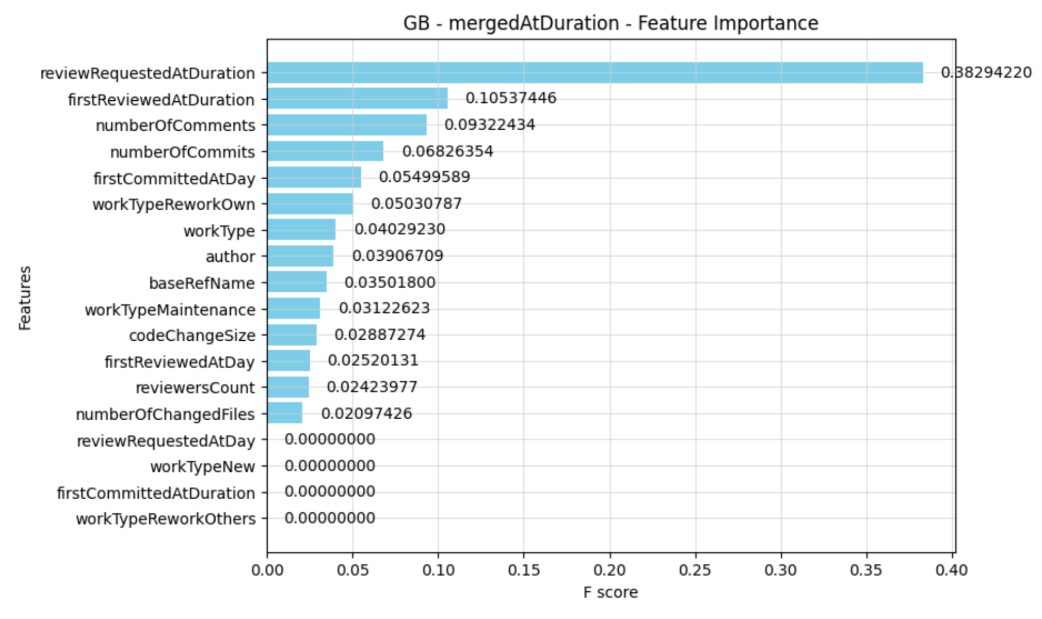
For that purpose we mapped the so-called F-score, which is a number that indicates how well each feature contributes to the model's predictive ability. The higher the F-score, the more relevant a feature is in distinguishing characteristics between merged and unmerged pull requests. It turns out that significant features are when a review was requested, the number of PR comments and the number of commits. To our surprise, the code change size was actually less relevant.
Example F-scores on PR properties to examine predictability.
Model tuning. To keep the model accurate, we regularly checked its performance and updated it with new data. As team dynamics, coding practices, and project scopes evolve, continuous refinement ensures the model remains relevant and effective to particular teams or organisations. The more data we processed, the better the model becomes at identifying bottlenecks and providing actionable insights.
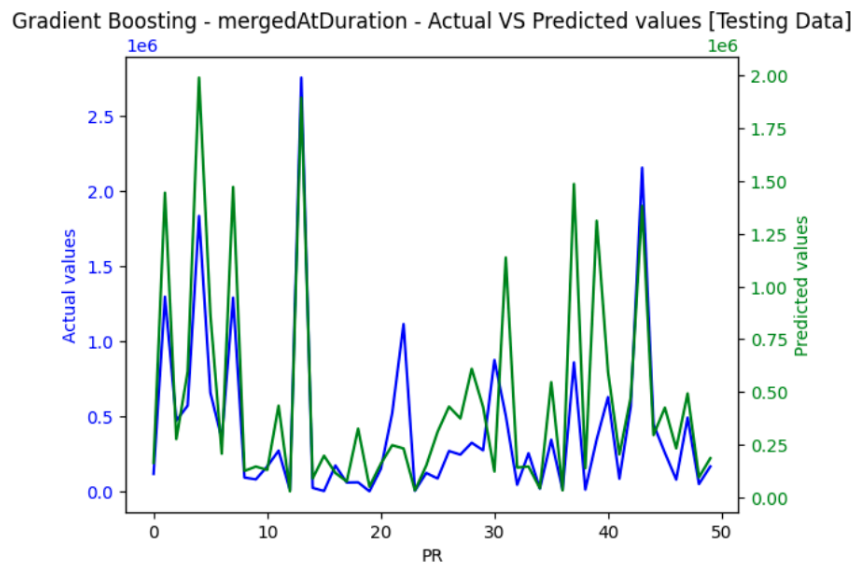
Below we plotted the actual and predicted cycle times. This provides a clear picture of how well the model is performing, enables us to spot trends, patterns, and any mismatches between expected and predicted results. For noticeable differences we fine-tuned the model - whether by tweaking features, adjusting settings, or improving how the data is processed - to make predictions more accurate. Big gaps between the actual and predicted values can signal hidden complexities in PR data that the model hasn’t fully picked up on and requires further investigation.
Actual PR merge times (blue) vs the predicted merge times (green).
Results. We used several machine learning models, including Gradient Boosting, Linear Regression, Support Vector Machine (SVM), and Bayesian Ridge to predict different PR properties including there merge times.
In our experience Gradient Boosting was the most accurate, while Linear Regression was the most stable and reliable. Unfortunately, the Support Vector Machine model didn’t perform well, showing that not all machine learning models work equally well for this task.
We used various statistical metrics, including R² (R-squared), MAE (Mean Absolute Error), and RMSE (Root Mean Squared Error), to validate the performance of each model. Each metric played its part: R² showed how well the model fit the data, MAE gave us a sense of the average prediction error, and RMSE helped us spot any bigger prediction mistakes. Together, these validation techniques gave us a clear picture of how accurate and reliable each model was. Time-based features, such as the when the first commit was made, and the number of comments and the work type(new work, refactoring, quick patch up) of the a PR, stood out as especially indicative to make accurate predictions.
Conclusion
At the end of the day, our goal of applying AI use is to make life easier for developers and their managers. Whether it’s predicting slow-moving reviews, flagging complex PRs that require extra attention, or streamlining the merge process. AI-driven insights can significantly enhance workflow management and overall productivity.
While these are early results we discovered surprising correlations and quite helpful insights. We continue on improving the models and are working with our design partners to make those predictive capabilities available to our wider user base in the future.
Logilica ML Architecture
With more accurate predictions, fewer delays, and a smoother workflow, integrating ML into the PR process is a no-brainer. As technology keeps evolving, so will the ways we optimise our development workflows. With that the future of software development might just be a little smarter, faster, and more efficient!




.jpeg)